Plan and organize the synchronization of your QE Score data collection.
- qescore
- Apr 7
- 3 min read

Updated: 6 days ago
The "QE Score" is a living indicator: for it to accurately reflect the reality of an application, it must be supplied with fresh, up-to-date data. Collecting data on a one-off basis or too far in advance can distort the analysis and mask any drifting trends. That's why it's crucial to implement a strategy of regular, even daily, data collection for certain data sources such as SonarQube, Jira or GitLab. This regularity ensures the reliability, responsiveness and accuracy of the score, providing a real-time view of project quality. The choice of data collection method - synchronous or asynchronous - then becomes strategic.

The challenges of collecting quality metrics
Disparate tools: UI tests, APIs, security, performance, code quality, etc. Metrics are scattered across different tools and platforms.
Frequency and updating of data: Some metrics are updated in real time, while others are updated less frequently, which complicates their analysis.
Complexity of integration: Retrieving and centralising this data often requires specific developments and time.
Synchronous mode: immediate and reliable, but more demanding
Synchronous mode is based on event-driven operation: each time an event occurs (e.g. a SonarQube analysis ends, a Jira ticket changes status, a commit is made to GitLab, a functional test automaton ends), the data is immediately sent to the database or Google Sheet.
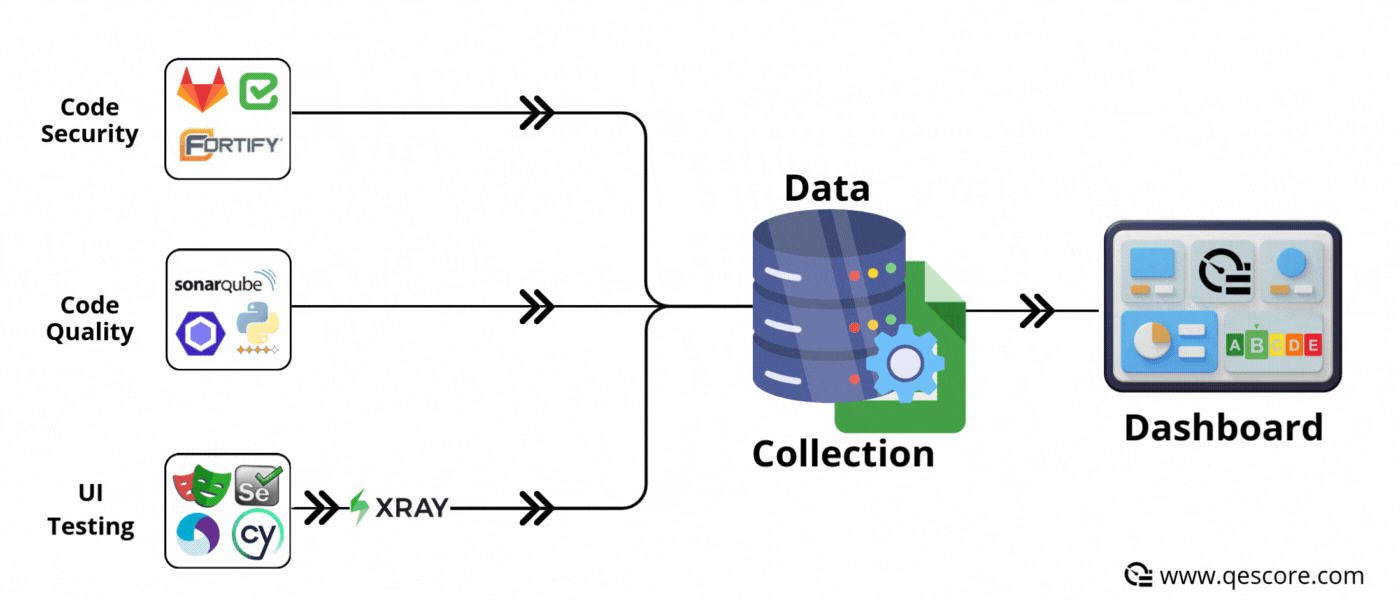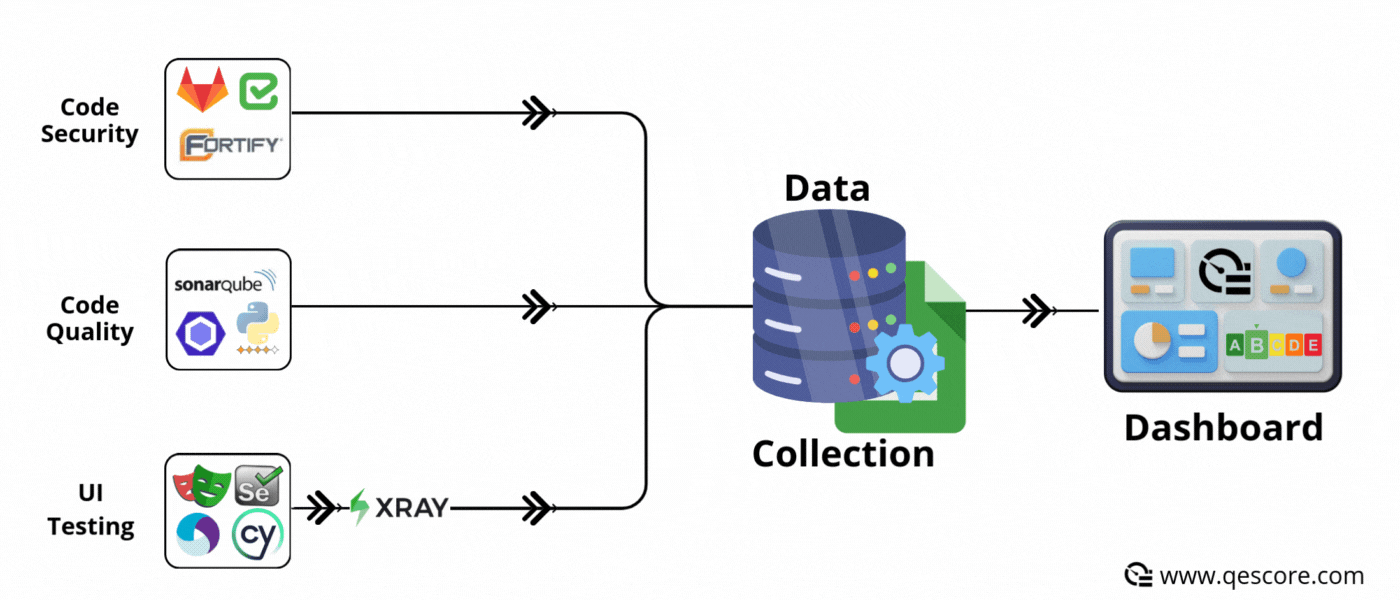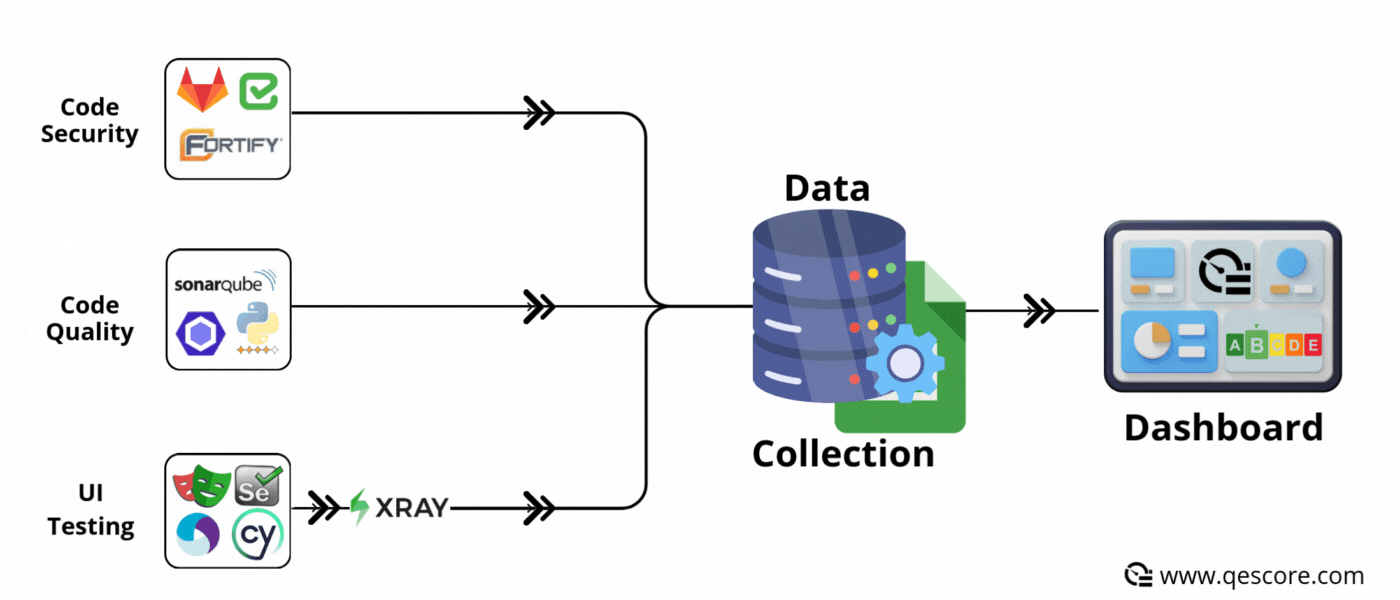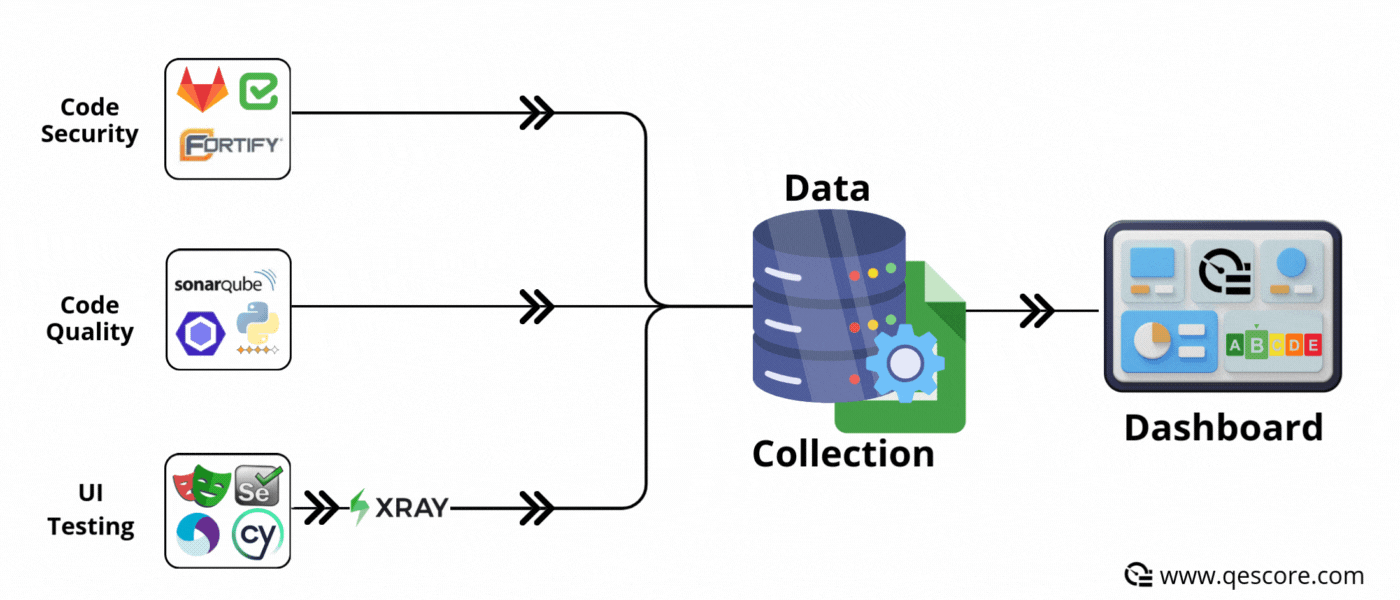
✅ Advantages :
Real-time data: information is updated as soon as an event occurs.
Fewer unnecessary requests: no need to scrape or regularly query APIs, which reduces network load and API costs.
Greater reliability: the QE Score accurately reflects the current situation.
⚠️ Disadvantages :
More complex implementation: each tool must have a sending module (e.g. webhook, event hook, external service).
Tool dependency: not all tools support this type of integration without addition or adaptation.
Additional maintenance: if the API or event changes, the sending modules need to be updated.
Asynchronous mode: easy to deploy, but less responsive
Asynchronous mode works by periodic interrogation: a script or the Google Sheet itself retrieves data from the APIs at defined intervals (every hour, every night, etc.).

✅ Advantages :
Easy to set up: no need to modify tools or add modules, a simple API call is all that's needed.
Standardised: works with all tools that have an API, without complex configuration.
Ideal for a first level of automation: provides relatively fresh data without any major technical effort.
⚠️ Disadvantages :
Potentially obsolete data: there may be a time lag between when an event occurs and when it is retrieved.
Regular, sometimes pointless requests: if the data has not changed, API calls are redundant and consume resources.
Less suitable for real-time use: a QE Score updated only at night will not reflect changes during the day.

A hybrid approach: combining the best of synchronous and asynchronous for your QE Score
The most effective solution for guaranteeing a reliable and up-to-date QE Score is often a hybrid approach, combining the two modes of data collection: synchronous for critical data that is readily available in real time, and asynchronous for other data.

🧩 How does it work?
For some data, synchronous mode is simple to set up. For example, at the end of a CI/CD pipeline, an automatic call is made to send SonarQube results (technical debt, test coverage, etc.) directly to the database or Google Sheet.
For data that does not yet have a sending mechanism or that is more difficult to integrate, we supplement this with an asynchronous mode, based on regular scheduling.
📅 Frequencies adapted to each type of data :
Code security: security flaws can be recovered several times a day.
Functional and performance tests: daily recovery is sufficient, often after a scheduled night-time run.
Project quality (e.g. open tickets, bugs): every 2 or 4 hours, depending on the pace of the project.
GitLab activity: 1 to 2 times a day to track commits, MRs, etc.
✅ Advantages of this approach:
Enables a gradual transition to synchronous, without implementing everything at once.
Optimises the technical effort: resources are invested as a priority where the impact on data freshness is greatest.
Avoids wasting resources on data that doesn't evolve much.
⚠️ Points to watch out for:
Requires good organisation: you need to map the data sources, monitor how often they are updated, and make sure you don't forget any data.
🔐 Conclusion: The success of the QE Score depends as much on the quality of the calculation as on the freshness and reliability of the data. A well-organised hybrid approach is therefore the key to ensuring its relevance and user confidence.
Et pour vous, quel est la meilleure solution de planification de collecte de la données ?
hybride
asynchrone
synchrone
autre approche
Comments